

Was sind denn objektrelationale Datenbanken?
Objektrelationale DB sind eine Erweiterung relationaler DB. Ein Attribut kann hier auch eine Menge von Werten statt einem atomaren Attribut sein, die OODB erfüllen also nicht zwangsläufig die 1NF.
Der Vorteil ist, dass man N:M-Relationen zusammenfassen kann, die nicht-atomaren Mengen sind dabei Referenzen auf Daten, die in anderen Relationen gespeichert sind. Attribute können auch selber wieder Relationen sein. Neben User-defined Types können Objekte auch spezialisiert werden. Alle Tupel der Unter-Relation sind dann implizit auch in der Ober-Relation enthalten.
Um das in 1NF zu bringen, muss sich die Anwendung selbst darum kümmern.
Der Vorteil ist, dass man N:M-Relationen zusammenfassen kann, die nicht-atomaren Mengen sind dabei Referenzen auf Daten, die in anderen Relationen gespeichert sind. Attribute können auch selber wieder Relationen sein. Neben User-defined Types können Objekte auch spezialisiert werden. Alle Tupel der Unter-Relation sind dann implizit auch in der Ober-Relation enthalten.
Um das in 1NF zu bringen, muss sich die Anwendung selbst darum kümmern.
Tags: objektrelational, oodbms
Source: MMDB 2009 Kapitel 3
Source: MMDB 2009 Kapitel 3
Was ist der Unterschied zwischen einer MMDB und einer DB?
Multimedia-Daten haben eine Semantik. Sie uninterpretiert zu speichern und zu durchsuchen bringt nicht viel, relationale DBMS sind auf Text- und Zahlenwerte ausgelegt. Das Ziel einer MMDB ist die inhaltsbasierte Suche, die MM-Daten werden strukturiert gespeichert. Beispielanfrage: "Zeige mir alle Bilder von Häusern vor einem blauen Himmel"
Die Suche selbst wird als Erweiterung von Information Retrieval implementiert, die neben klassischen Relationen die Mediendaten durchsuchen lamm.
Die Suche selbst wird als Erweiterung von Information Retrieval implementiert, die neben klassischen Relationen die Mediendaten durchsuchen lamm.
Was für Information Retrieval-Modelle (Anfragemodelle) gibt es?
- Boolesches Modell: Menge von Indextermen mit booleschen Junktoren für Query und Dokumente ("Koblenz AND Billiard"), entweder in DNF (kompaktere Zwischenergebnisse) oder KNF normalisiert. Unintuitiv, keine Relevanzabstufung, keine Ähnlichkeitssuche, große Ergebnismengen.
- Fuzzy-Modell: Boolesches Modell um Zugehörigkeitswerte erweitert.. Boolesche Anfrage wird in eine Funktion überführt, die für jedes Dokument die Zugehörigkeit zwischen 0 und 1 zurückliefert. Ergebnisse über Schwellwert, dann sortiert.
- Verkorraum-Modell: Dokumente und Anfrage als Vektoren gleicher Länge (eine Dimension pro Feature). Ähnlichkeit über Kosinusmaß, der Kosinus des eingeschlossenen Winkels zwischen beiden Vektoren
 oder Distanzfunktion als Unähnlichkeitsmaß (schlecht für Textdokumente wegen unterschiedlicher Wortanzahl und daher unterschiedlicher Vektorlänge). VR-Modell kann prinzipiell mit Fuzzy-Modell kombiniert werden (Vektoren als Furry-Anfragen).
oder Distanzfunktion als Unähnlichkeitsmaß (schlecht für Textdokumente wegen unterschiedlicher Wortanzahl und daher unterschiedlicher Vektorlänge). VR-Modell kann prinzipiell mit Fuzzy-Modell kombiniert werden (Vektoren als Furry-Anfragen).Tags: information retrieval, modelle
Source: MMDB 2009
Source: MMDB 2009
Wie können Anwender die Suchergebnisse verfeinern?
Man könnte
Üblicherweise muss der Anwender seine Suche selbst anpassen (etwa bei Google). Alternativ könnte man Relevance Feedback anbieten.
- die Anfrage verändern (hier beschrieben)
- nutzerprofile verwenden
- dokumentbeschreibungen anpassen
- den Suchalgorithmus modifizieren
- Anfragetermgewichte modifizieren
Üblicherweise muss der Anwender seine Suche selbst anpassen (etwa bei Google). Alternativ könnte man Relevance Feedback anbieten.
Tags:
Source: MMDB 2009 Kapitel 4
Source: MMDB 2009 Kapitel 4
Wie funktioniert Relevance Feedback?
Der Anwender markiert relevante und irrelevante Dokumente. Es geht auch über Pseudorelevanz, wo das System selber die nach seiner Meinung relevanten Dokumente aussucht (manuell ist aber besser).
Nach der Methode von Rocchio kann man aus dem alten Anfragevektor anhand der Bewertungen einen neuen machen, indem er in die Richtung der relevanten Dokumente verschoben wird:
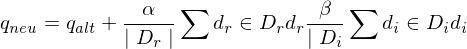 , wobei
, wobei 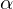 und
und 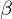 Gewichte für relevant und irrelevant sind,
Gewichte für relevant und irrelevant sind, 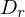 und
und 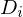 die Menge der relevanten bzw. irrelevanten Dokumente sind.
die Menge der relevanten bzw. irrelevanten Dokumente sind.
Nach der Methode von Rocchio kann man aus dem alten Anfragevektor anhand der Bewertungen einen neuen machen, indem er in die Richtung der relevanten Dokumente verschoben wird:
, wobei und Gewichte für relevant und irrelevant sind, und die Menge der relevanten bzw. irrelevanten Dokumente sind.Wie können wir denn Retrieval-Systeme bewerten?
Dazu unterschieden wir vier Stati von Dokumenten unterscheiden:
Darauf können Qualitätsmaße aufgebaut werden: Precision, Recal, Fallout
- false alarms: Als relevant eingestuft aber irrelevant
- false dismissals: Als irrelevant eingestuft aber relevant
- correct alarams: Korrekt als relevant eingestuft
- correct dismissals: Korrekt als irrelevant eingestuft
Darauf können Qualitätsmaße aufgebaut werden: Precision, Recal, Fallout
Tags:
Source: MMDB 2009 Kapitel 4
Source: MMDB 2009 Kapitel 4
Wie funktionieren Precision, Recall und Fallout?
Es sind Qualitätsmaße, die wie folgt definiert sind:
Alle drei Werte liegen zwischen 0 und 1. Precision und Recall sollten maximiert, Fallout minimiert werden. Üblicherweise werden P und R zueinander in Verhältnis gesetzt, z.B. als x- und y-Achsen in einem Diagramm. Um Sägezahn zu vermeiden, wird dabei das harmonische Mittel genommen (x-Achse Anzahl Ergebnisdokumente, y-Achse HM), je näher an 100% desto besser.
- Precision beschreibt, wie gut das System false alarms verhindert.

- Recall beschreibt, wie gut das System false dismissals verhindert.
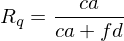
- Fallout ist das Verhältnis von fälschlicherweise gefundenen Dokumenten zu der Gesamtanzahl irrelevanter Dokumente
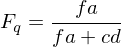
Alle drei Werte liegen zwischen 0 und 1. Precision und Recall sollten maximiert, Fallout minimiert werden. Üblicherweise werden P und R zueinander in Verhältnis gesetzt, z.B. als x- und y-Achsen in einem Diagramm. Um Sägezahn zu vermeiden, wird dabei das harmonische Mittel genommen (x-Achse Anzahl Ergebnisdokumente, y-Achse HM), je näher an 100% desto besser.
Was ist jetzt beim Multimedia-Retrieval anders?
- Große Datenmengen, daher meist Komprimierung oder Vorverarbeitung nötig
- Semantik nur implizit vorhanden, Daten müssen interpretiert werden, daher üblicherweise Extraktion von Features
- Heterogenität durch Medien- und Formatvielfalt. Daher Medien-Umsetzung (Text in Audio), Formatumwandlung oder Metadaten zu Medientyp und -format.
- Komplexe Medienobjekte durch Kombination verschiedener Medientypen, Referenzen, Einbettung. Daher Zerlegung in nicht-komplexe Objekte.
- Ein- und Ausgabegeräte, z.B. Suche nach Audio erfordert Mikrofon.
Tags:
Source: MMDB 2009 Kapitel 5
Source: MMDB 2009 Kapitel 5
Was passiert beim Multimedia Information Retrieval?
- Einfügen: Die relationalen Daten (Metadaten wie Typ, Format, Name, ...) werden in eine relationale DB gespeichert. Komplexe Objekte werden in primitive zerlegt, die Struktur wird aber für die Rekonstruktion gespeichert. Objekte werden ggf. normalisiert.
- Feature-Extraktion: Ein Feature ist ein inhaltstragender Eigenschaftswert eines Medienobjekts. Die Features sind eine kompakte Form des Objekts und sind die Grundlage der Ähnlichkeitsberechnung. Die Berechnung hängt vom Medientyp, beabsichtiger Ähnlichkeitsberechnung und verfügbaren Extraktionsalgorithmen ab. Nach der E kommt die Aufbereitung (skalieren, Abhängigkeiten beseitigen, überflüssige F entfernen). Abschließend werden die F für schnellen Zugriff indiziert.
To be continued...
Tags:
Source: MMDB 2009 Kapitel 5
Source: MMDB 2009 Kapitel 5
Was passiert beim Multimedia-IR weiter?
- Anfrageaufbereitung: Normale Anfragen (DR) werden optimiert, indem durch Selektion die Zwischenergebnisse möglichst minimal gehalten werden können. Bei der Ähnlichkeitssuche (QBE) wird die Anfrage wie oben beschrieben bearbeitet.
- Anfragebearbeitung: Bei DR werden die Daten normal ausgelesen. Bei QBE werden mit Hilfe einer Ähnlichkeitsfunktion die ähnlichsten DB-Objekte gefunden (über den Index). Komplexe Anfragen werden in einfache zerlegt und dann gejoined. DR und QBE können auch kombiniert werden.
- Ergebnisaufbereitung: Ggf. Formatumwandlung, Rekonstruktion oder Anpassung an Geräte- und Nutzerprofile bei der Anzeige nötig. Nutzer muss mit interaktiven Ergebnissen (Video...) interagieren können.
- Relevance Feedback
Worauf muss man bei der Feature-Extraktion achten?
Anforderungen an die FE:
- Adäquatheit: Die berechneten Werte einer Eigenschaft müssen diese Eigenschaft auch tatsächlich angemessen ausdrücken
- effiziente Berechnung
- Berücksichtigung von Invarianzen: Unabhängigkeit von ungewollten Eigenschaften wie verfälschende Lichtverhältnisse, Rotation etc
- Minimalität: Die Eigenschaft wird mit einer minimalen Anzahl von Feature-Werten ausgedrückt.
- Orthogonalität: Die Feature-Werte sind voneinander unabhängig (sonst ist keine isolierte Bearbeitung der Daten möglich).
Tags:
Source: MMDB 2009 Kapitel 5
Source: MMDB 2009 Kapitel 5
Wie erreiche ich die Unabhängigkeit von ungewollten Eigenschaften der Features?
Die Berechnung eines Haar-Integrals auf einer Feature-Extraktionsfunktion 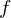 ermöglicht die Konstruktion einer Feature-Extraktionsfunktion
ermöglicht die Konstruktion einer Feature-Extraktionsfunktion  , die invariant bezüglich einer parametrisierbaren Transformationsfunktion
, die invariant bezüglich einer parametrisierbaren Transformationsfunktion 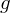 ist. Um eine Invarianz von zu erreichen, wird der Durchschnitt der extrahierten Feature-Werte über den Anwendungen aller möglichen Transformationsfunktionen berechnet. Das Haar-Integra wird definiert wie folgt:
ist. Um eine Invarianz von zu erreichen, wird der Durchschnitt der extrahierten Feature-Werte über den Anwendungen aller möglichen Transformationsfunktionen berechnet. Das Haar-Integra wird definiert wie folgt:

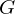 ist dabei die Menge aller Transformationsfunktionen, die durch unterschiedliche Parametrisierungen von erreicht werden kann. Für den Praxis-Einsatz sind Integrale eher hinderlich. Da unsere Objekte im diskreten Raum liegen und G eine endliche Menge ist, kann das Haar-Integral so geschrieben werden:
ist dabei die Menge aller Transformationsfunktionen, die durch unterschiedliche Parametrisierungen von erreicht werden kann. Für den Praxis-Einsatz sind Integrale eher hinderlich. Da unsere Objekte im diskreten Raum liegen und G eine endliche Menge ist, kann das Haar-Integral so geschrieben werden:
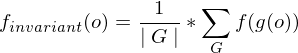
ermöglicht die Konstruktion einer Feature-Extraktionsfunktion , die invariant bezüglich einer parametrisierbaren Transformationsfunktion ist. Um eine Invarianz von zu erreichen, wird der Durchschnitt der extrahierten Feature-Werte über den Anwendungen aller möglichen Transformationsfunktionen berechnet. Das Haar-Integra wird definiert wie folgt: ist dabei die Menge aller Transformationsfunktionen, die durch unterschiedliche Parametrisierungen von erreicht werden kann. Für den Praxis-Einsatz sind Integrale eher hinderlich. Da unsere Objekte im diskreten Raum liegen und G eine endliche Menge ist, kann das Haar-Integral so geschrieben werden:Tags:
Source: MMDB 2009 Kapitel 5
Source: MMDB 2009 Kapitel 5
Wie gut eignen sich die Retrieval-Modelle für Multimedia-Retrieval?
- Boolesches Modell: Aufgrund der zu scharfen/exakten Semantik wenig geeignet, graduelle Ähnlichkeitssuche nicht unterstützt.
- Fuzzy-Modell: Besser als Boolesches Modell wegen den Zugehörigkeitswerten. Junktoren auf Zugehörigkeitswerten ermöglichen komplexe Anfragen. Ähnlichkeitsanfragen können mit relationalen Anfragen kombiniert werden.
- Vektorraum-Modell: Feature-Werte als geometrische Objekte im Vektorraum, wodurch Verfahren der linearen Algebra einsetzbar sind. Es existieren viele verschiedene Distanz- und Ähnlichkeitsfunktionen. Durch seine Allgemeinheit gut einsetzbar.
Tags:
Source: MMDB 2009 Kapitel 5
Source: MMDB 2009 Kapitel 5
Was ist Information Retrieval?
Die Anfrage mit Hilfe einer exakt formulierter Bedingung bei einer relationalen DB nennt man Data Retrieval. Bei Information Retrieval versucht man, Dokumente zu finden, die eine inhaltliche Relevanz zur Anfrage haben. Die Suchanfrage ist dabei i.d.R. unscharf formuliert.
Die Stärke von IR-Systemen liegt bei schwach strukturierten Dokumenten wie Text, Daten, die nur schwer in einem DB-Schema strukturiert werden können.
Die Anfrage kann dabei als Dokument (Query by Example) sein, bei dem ähnliche Dokumente zurückgeliefert werden, oder als Anfrage.
Die Schritte bei der Anfrage sind:
1. Verarbeitung, Extraktion, Überführung in eine interne Darstellung von Dokumenten und Anfrage.
2. Vergleich der internen Darstellung, gibt Relevanzwert.
3. Ergebnis wird sortiert und ggf. durch Schwellwert auf Relevanz eingeschränkt.
4. Relevanzbewertung und Feedback, ggf. Anfrageiteration.
Die Stärke von IR-Systemen liegt bei schwach strukturierten Dokumenten wie Text, Daten, die nur schwer in einem DB-Schema strukturiert werden können.
Die Anfrage kann dabei als Dokument (Query by Example) sein, bei dem ähnliche Dokumente zurückgeliefert werden, oder als Anfrage.
Die Schritte bei der Anfrage sind:
1. Verarbeitung, Extraktion, Überführung in eine interne Darstellung von Dokumenten und Anfrage.
2. Vergleich der internen Darstellung, gibt Relevanzwert.
3. Ergebnis wird sortiert und ggf. durch Schwellwert auf Relevanz eingeschränkt.
4. Relevanzbewertung und Feedback, ggf. Anfrageiteration.
Tags:
Source: MMDB 2009 Kapitel 4
Source: MMDB 2009 Kapitel 4
Welche Feature-Transformationsverfahren kennen wir?
Wir kennen:
- Die diskrete Fourier-Transformation (Ortsraum->Frequenzraum)
- Die diskrete Wavelet-Transformation (Ortsraum->lokal begrenzte Frequenzräume)
- Karhunen-Loeve-Transformation (Minimalität einer Menge von Medienobjekten)
- Latent Semantic Indexing (ähnlich KLT)
Wie funktioniert die diskrete Fourier-Transformation?
Jede periodische Funktion kann als die Summe von Sinus- und Kosinusfunktionen dargestellt werden, die FT übernimmt diese Umwandlung. Sie überführt also eine Funktion vom Ortsraum in den Frequenzraum.
Anwendung:
Die DFT kann man als Matrixmultiplikation auffassen, die Rücktransformation geschieht mit der Adjungierten Matrix. Es ist eine Rotation im Raum, die euklidischen Distanzen sind im Orts- und Frequenzraum gleich.
Anwendung:
- Feature-Aufbereitung: Für weitere Bearbeitung unwichtige Frequenzen ausfiltern, um Minimalität des Signals zu erreichen.
- Feature-Normalisierung: Den Einfluss verschiedener Störfaktoren innerhalb von Medienobjekten unterdrücken. Diese sind oft auf bestimmte Frequenzbereiche konzentriert -> entfernen, dann rücktransformieren.
- Feature-Erkennung: Manche zu extrahierende Eigenschaften korrespondieren zu bestimmten Frequenzen. Ausserdem im Frequenzbereich Verschiebungsinvariant.
Die DFT kann man als Matrixmultiplikation auffassen, die Rücktransformation geschieht mit der Adjungierten Matrix. Es ist eine Rotation im Raum, die euklidischen Distanzen sind im Orts- und Frequenzraum gleich.
Tags:
Source: MMDB 2009 Kapitel 6
Source: MMDB 2009 Kapitel 6
Welche Vorteile hat die Wavelet-Transformation?
Der Nachteil der DFT ist, dass sich lokale Änderungen im einen Raum als globale Änderung im anderen Raum niederschlägt. Bei der Wavelet-Transformation werden Frequenzanteile für verschieden großen Intervalle berechnet.
Features können sich auch aus Orts- und Frequenzinformationen zusammensetzen. Ausserdem ist der Aufwand der WT O(n) statt ON(n*log n).
Angewendet wird die DWT zur:
Features können sich auch aus Orts- und Frequenzinformationen zusammensetzen. Ausserdem ist der Aufwand der WT O(n) statt ON(n*log n).
Angewendet wird die DWT zur:
- Feature-Normalisierung: Störfrequenzen können lokal entfernt werden. Mutterwavelet kann an Störsignal angepasst werden.
- Feature-Erkennung/Aufbereitung: Lokale Frequenz-Analyse, etwa Textur-Analyse.
Tags:
Source: MMDB 2009 Kapitel 6
Source: MMDB 2009 Kapitel 6
Wie geht man bei der zweidimensionalen DWT vor?
Es gibt zwei Verfahren:
- Standardzerlegung: DWT wird komplett auf allen Zeilen durchgeführt, Ergebnis als 2D-Funktion aufgefasst. Auf diese wird die DWT auf alle Spalten ausgeführt.
- Nonstandard-Zerlegung: Alternierend pro neuer Auflösungsstufe zwischen beiden Dimensionen wechseln.
Welche Eigenschaften können Distanzfunktionen haben?
| Klasse | Selbstidentität | Positivität | Symmetrie | Dreiecksu. |
| Distanzfunktion | x | x | x | x |
| Pseudo-DF | x | - | x | x |
| Semi-DF | x | x | x | - |
| Semi-Pseudo-DF | x | - | x | - |
Selbstidentität:

Positivität:
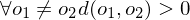
Symmetrie:
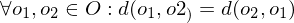
Dreiecksungleichung:
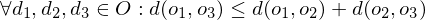
Tags:
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Erklären sie die Minkowsi-DF
Die Minkowski-DF ist die Verallgemeinerung der euklidischen und Cityblock-Distance:
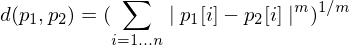
Also Manhattan/Cityblock-Distance mit m=1, euklidische mit m=2.
Sie ist für m=2 rotationsinvariant (Einheiskreis), und immer translationsinvariant.
Also Manhattan/Cityblock-Distance mit m=1, euklidische mit m=2.
Sie ist für m=2 rotationsinvariant (Einheiskreis), und immer translationsinvariant.
Tags:
Source: MMDB 2009
Source: MMDB 2009
Wofür brauchen wir hochdimensionale Indexstrukturen? Was macht diese aus?
Indextrukturen dienen der effizienten Suche. Da Medienobjekt meist mehrdimensionale Features haben und die Schnittmengenbildung auf eindimensionalen Indexstrukturen suboptimal ist, werden hochdimensionale Indexstrukturen benötigt.
MI sollten
MI sollten
- korrekte und vollständige Ergebnisse finden
- bezüglich ihrer Dimensionen skalierbar sein (hochdimensional)
- Suche nach verschiedendimensionalen Objekten ermöglichen
- mit höchstens linearem Aufwand suchen
- möglichst viele Anfragearten unterstützen
- Updates effizient durchführen können
- verschiedene Distanzfunktionen erlauben
- möglichst speichersparend sein
Tags:
Source: MMDB 2009
Source: MMDB 2009
Welche Anfragearten für die Suche in Bäumen gibt es?
- Nächste-Nachbar oder K-Nächste-Nachbar-Suche
- Approximative Nächste-Nachbar-Suche
- Reverse Nächste-Nachbar-Suche (Wer hat den Anfragepunkt als nächsten Nachbarn). Ergebnis oft anders als NN da Nachbar-Relation nicht symmetrisch.
- Bereichssuche
- Partial-Match-Suche (Übereinstimmung in einigen Dimensionen)
- Ähnichkeitsverbund
Tags: baum, eigenschaften, mehrdimensional
Source: MMDB 2009
Source: MMDB 2009
Wie kann man Bäume klassifizieren?
| Merkmal | Unterscheidung |
| Cluster-Bildung | global-zerlegend vs. lokal gruppierend |
| Cluster-Überlappung | überlappend vs. disjunkt |
| Balance | balanciert vs. unbalanciert |
| Objektspeicherung | Blätter und Knoten vs. Blätter |
| Geometrie | Hyperkugel, Hyperquader, Hyperellipsoid... |
Wie funktioniert der Branch-and-Bound-Algorithmus?
Die Idee des BaB-Algo ist, Teilbäume von der Suche auszuschließen, wenn der Mindestabstand dieses Teilbaums
Eingabedaten sind ein Referenzpunkt p und ein Startknoten im Baum T.
Es wird eine obereGrenze mitgeführt (am Anfang unendlich), und eine Referenz auf den nächsten Nachbarn NN.
Nun wird T nach der lb-Distanz aufsteigend sortiert. Die lb-Distanz ist die kleinste quadratische Distanz zwischen Punkt und Cluster. Nun über sortiertes T iterieren:
Ist k aus T ein Blatt, so wird für jeden Punkt p aus k geprüft, ob die Distanz kleiner als obereGrenze ist. Falls ja: obereGrenze auf dist(k), NN=p.
Wenn k kein Blatt ist, wird geprüft, ob die kleinstmöglichste Distanz von q zu k größer ist als obereGrenze. Falls ja, wird der Knoten ignoriert, ansonsten wird BaB rekursiv auf k aufgerufen.
Eingabedaten sind ein Referenzpunkt p und ein Startknoten im Baum T.
Es wird eine obereGrenze mitgeführt (am Anfang unendlich), und eine Referenz auf den nächsten Nachbarn NN.
Nun wird T nach der lb-Distanz aufsteigend sortiert. Die lb-Distanz ist die kleinste quadratische Distanz zwischen Punkt und Cluster. Nun über sortiertes T iterieren:
Ist k aus T ein Blatt, so wird für jeden Punkt p aus k geprüft, ob die Distanz kleiner als obereGrenze ist. Falls ja: obereGrenze auf dist(k), NN=p.
Wenn k kein Blatt ist, wird geprüft, ob die kleinstmöglichste Distanz von q zu k größer ist als obereGrenze. Falls ja, wird der Knoten ignoriert, ansonsten wird BaB rekursiv auf k aufgerufen.
Tags:
Source: MMDB 2009
Source: MMDB 2009
Wie funktioniert der RKV-Algorithmus?
Der RKV-Algo ist ein modifizierter Branch-and-Bound-Algo. Er setzt voraus, dass ein Baum mit lokaler Gruppierung, Minimum Bounding Rectangles (MBRs) als Cluster-Geometrie und Feature-Objekten nur in den Blättern vorliegt.
Die Kindknoten werden anhand der MIN- (optimistisch) oder MINMAX-Dist (pessimistisch) sortiert. Die sortierten Kindknoten werden in der Active Branch List verwaltet. Es gibt drei Strategien, um nicht die gesamte ABL durchsuchen zu müssen:
1. Alle Knoten mit MIN-Dist > MINMAX-Dist entfernen.
2. obereGrenze auf kleinste MINMAX-Dist setzen.
3. Alle Knoten mit MINMAX-Dist > obereGrenze entfernen.
Für KNN-Anfragen: Sortierte Warteschlange mit k NN-Kandidaten, obereGrenze ist Distanz zum letzten Kandidat.
Die Kindknoten werden anhand der MIN- (optimistisch) oder MINMAX-Dist (pessimistisch) sortiert. Die sortierten Kindknoten werden in der Active Branch List verwaltet. Es gibt drei Strategien, um nicht die gesamte ABL durchsuchen zu müssen:
1. Alle Knoten mit MIN-Dist > MINMAX-Dist entfernen.
2. obereGrenze auf kleinste MINMAX-Dist setzen.
3. Alle Knoten mit MINMAX-Dist > obereGrenze entfernen.
Für KNN-Anfragen: Sortierte Warteschlange mit k NN-Kandidaten, obereGrenze ist Distanz zum letzten Kandidat.
Tags: mehrdimensional index rkv
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Wie funktioniert der HS-Algorithmus?
Der HS-Algorithmus verwendet statt einer Tiefensuche eine global sortierte Warteschlange mit Knoten, Blätter und Feature-Objekten mit minimaler Distanz lb zum Anfragepunkt:
1. Mit Wurzel initialisieren
2. Wenn entnommenes Kopfelement Knoten, dann werden Kinder eingefügt.
2. Wenn entnommenes Kopfelement Blatt, dann werden Feature-Objekte eingefügt.
2. Wenn entnommenes Kopfelement Feature-Objekt, dann fertig
Gut für getNext-Anfragen geeignet, aber viel Speicher nötig und keine Tiefen/Breitensuche und daher kein sequentieller Festplattenzugriff
Aufwand, um alle FOs auszugeben ist O(n * log(n))
1. Mit Wurzel initialisieren
2. Wenn entnommenes Kopfelement Knoten, dann werden Kinder eingefügt.
2. Wenn entnommenes Kopfelement Blatt, dann werden Feature-Objekte eingefügt.
2. Wenn entnommenes Kopfelement Feature-Objekt, dann fertig
Gut für getNext-Anfragen geeignet, aber viel Speicher nötig und keine Tiefen/Breitensuche und daher kein sequentieller Festplattenzugriff
Aufwand, um alle FOs auszugeben ist O(n * log(n))
Tags: hs, indexstruktur, mehrdimensional
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Welche Eigenschaften hat der R-Baum?
Ist eine Erweiterung des B-Baums um mehrere Dimensionen. FOs können beliebige räumliche Ausdehnung haben.
Cluster-Bildung: lokal gruppierend.
Cluster-Überlappung: Können überlappen, führt zu weniger effizienter Suche
Balance: Ist balanciert durch Split-Algorithmus beim Seitenüberlauf und Seitenzusammenfassung beim Unterlauf.
Objektspeicherung: Nur in den Blättern.
Geometrie: MBR
Anzahl der Kindknoten: An Seitengröße angepasst.
Cluster-Bildung: lokal gruppierend.
Cluster-Überlappung: Können überlappen, führt zu weniger effizienter Suche
Balance: Ist balanciert durch Split-Algorithmus beim Seitenüberlauf und Seitenzusammenfassung beim Unterlauf.
Objektspeicherung: Nur in den Blättern.
Geometrie: MBR
Anzahl der Kindknoten: An Seitengröße angepasst.
Tags: baum, mehrdimensional, r-baum
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Wie kann man mit dem R-Baum arbeiten?
Einfügen:
Suche geht über BaB, HS- und RKV-Algorithmen. Bei Bereichsanfragen muss man in jeden Unterbaum navigieren, dessen MBR den Suchbereich schneidet. Ab Dimension 10 ist NN-Suche nicht mehr effizient. Ausserdem bei hohen Dimensionen stärkere Überlappung -> hoher Suchaufwand
- Von der Wurzel ausgehend den Kindknoten suchen, dessen Volumen nur minimal erweitert werden müsste.
- Ist dies nicht eindeutig, den Kindknoten wählen, dessen Volumen das kleinste ist.
- Objekt einfügen und Vaterknoten anpassen.
- Wenn ein Knoten überläuft, MBR in zwei kleinere MBR mit minimaler Volumensumme zerlegen. Es gibt verschiedene Algorithmen, üblicherweise nimmt man den linearen.
Suche geht über BaB, HS- und RKV-Algorithmen. Bei Bereichsanfragen muss man in jeden Unterbaum navigieren, dessen MBR den Suchbereich schneidet. Ab Dimension 10 ist NN-Suche nicht mehr effizient. Ausserdem bei hohen Dimensionen stärkere Überlappung -> hoher Suchaufwand
Tags: baum, mehrdimensional, r-baum
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Was ist der R+-Baum?
Der R+-Baum ist ein R-Baum ohne Überlappung und erfordert daher einen neuen Einfügealgorithmus. Ein Einfügen kann die Anpassung mehrerer Blätter erfordern. Wenn kein umfassender MBR gefunden werden kann, müssen Einträge mehrfach vorkommen. Ist trotzdem effizienter als R-Baum aber in hohen Dimensionen immer noch ineffizient.
Tags: baum, mehrdimensional, r-baum
Source:
Source:
Was ist der X-Baum?
Der X-Baum ist ein hybrider Baum, der mit hohen Dimensionen umgehen können soll. Die Idee ist, dass bei starker Überlappung ein sequentieller Durchlauf schneller ist als ein Baum. Dann werden Superknoten eingefügt, die beliebig viele DB-Seiten umfassen können und sequentiell durchsucht werden.
Tags: baum, mehrdimensional, x-baum
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Was passiert beim X-Baum beim Knotenüberlauf?
Jeder MBR verwaltet eine Split-Historie, die alle bereits verwendeten Zerlegungsdimensionen speichert.
Beim Überlauf wird nun
1. zuerst eine herkömmliche topologische Zerlegung gemacht.
2. wird ein vordefinierter Überlappungsgrad überschritten, so wird unter Ausnutzung der Split-Historie eine Zerlegungsdimension ausgesucht.
3. wird dadurch die Balance-Bedingung verletzt (Mindestfüllgrad), wird ein Superknoten erzeugt.
Ab etwa 15 Dimensionen wird der X-Baum zu einem einzigen Superknoten.
Beim Überlauf wird nun
1. zuerst eine herkömmliche topologische Zerlegung gemacht.
2. wird ein vordefinierter Überlappungsgrad überschritten, so wird unter Ausnutzung der Split-Historie eine Zerlegungsdimension ausgesucht.
3. wird dadurch die Balance-Bedingung verletzt (Mindestfüllgrad), wird ein Superknoten erzeugt.
Ab etwa 15 Dimensionen wird der X-Baum zu einem einzigen Superknoten.
Tags: baum, mehrdimensional, x-baum
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Was zeichnet den M-Baum aus?
Andere Bäume gehen davon aus, dass die FOs Elemente des euklidischen Raums sind. Nicht so der M-Baum. Die Distanzfunktion muss auch nur die Dreiecksungleichung erfüllen.
Cluster-Bildung: lokal gruppierend
Cluster-Überlappung: Erlaubt, wie beim R-Baum.
Balance: Balanciert wie R-Baum.
Objektspeicherung: Nur in Blättern.
Geometrie: Kugeln, also Punkte samt Radius.
Jeder innere Knoten hat folgende Struktur:
Blätter haben stattdessen ein FO, einen Zeiger auf das Medienobjekt und die Distanz vom FO zum o des Vater-Knotens.
Cluster-Bildung: lokal gruppierend
Cluster-Überlappung: Erlaubt, wie beim R-Baum.
Balance: Balanciert wie R-Baum.
Objektspeicherung: Nur in Blättern.
Geometrie: Kugeln, also Punkte samt Radius.
Jeder innere Knoten hat folgende Struktur:
- Zeiger zum Kindknoten
- Routing object o: FO, das Kugelzentrum ist
- Radius r. Maximal erlaubter Radius von o zu allen FOs im Teilbaum
- Distanz von o zum Routing Object des Vaterknotens.
Blätter haben stattdessen ein FO, einen Zeiger auf das Medienobjekt und die Distanz vom FO zum o des Vater-Knotens.
Tags: baum, m-baum, mehrdimensional
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Wie arbeitet man mit dem M-Baum?
Bei der Suche sind RKV und HS möglich. Die minimale Distanz (d(Op, Q)-d(O, Op)) gibt es in angenäherter Form als schnellen Filter. Cluster können mit der minimalen Distanz (d(o, Q) - r) und der Hilfe der Dreiecksungleichung ausgeschlossen werden.
Beim Einfügen analog zum R-Baum: Geeignetes Blatt ist das, dessen Radius nicht vergrößert werden muss (bei Gleichstand das mit dem nächstgelegenen Routing Object nehmen). Ansonsten das mit der minimalen Vergrößerung nehmen. Falls Radius verändert wurde, müssen die Radien auf dem Pfad bis zur Wurzel verändert werden.
Beim Überlauf muss ein Cluster in zwei neue Cluster mit eigenen Routing Objects zerlegt werden. Das Ziel ist, Volumen und Überlappung zu minimieren. Danach werden die FOs abwechselnd zugeordnet, um gleichgroße Cluster zu entwickeln.
Beim Einfügen analog zum R-Baum: Geeignetes Blatt ist das, dessen Radius nicht vergrößert werden muss (bei Gleichstand das mit dem nächstgelegenen Routing Object nehmen). Ansonsten das mit der minimalen Vergrößerung nehmen. Falls Radius verändert wurde, müssen die Radien auf dem Pfad bis zur Wurzel verändert werden.
Beim Überlauf muss ein Cluster in zwei neue Cluster mit eigenen Routing Objects zerlegt werden. Das Ziel ist, Volumen und Überlappung zu minimieren. Danach werden die FOs abwechselnd zugeordnet, um gleichgroße Cluster zu entwickeln.
Tags: baum, m-baum, mehrdimensional
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Was ist das Problem bei hohen Dimensionen? Was kann man tun?
Ab 20 Dimensionen versagt NN-Suche in Indexbäumen, es werden keine Teilbäume mehr ausgeschlossen, und ein sequentieller Durchlauf wäre effizienter: Der Fluch der hohen Dimensionen. Der Grund liegt in steigenden Approximationsfehlern und konstantem Abstand zwischen größter und kleinster Distanz. Das gilt auch für Metrik-Bäume wie den M-Baum.
Man kann versuchen:
Komplexe Distanzfunktionen durch einfache Distanzfunktion substituieren, solange diese Objekte korrekt ausschließt.
FastMap etwa bildet eine Metrik (Objekte und Distanzen) approximativ auf k-dimensionale Punkte und euklidische Distanzfunktionen ab.
Man kann versuchen:
Komplexe Distanzfunktionen durch einfache Distanzfunktion substituieren, solange diese Objekte korrekt ausschließt.
FastMap etwa bildet eine Metrik (Objekte und Distanzen) approximativ auf k-dimensionale Punkte und euklidische Distanzfunktionen ab.
Tags: baum, mehrdimensional, probleme
Source: MMDB 2009 Kapitel 7
Source: MMDB 2009 Kapitel 7
Was ist das Haar-Wavelet?
Das Haar-Wavelet ist die einfachste Wavelet-Transformation. Die Ausgangsfunktion ist eine Funktion mit 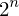 Funktionswerten. Diese Funktion wird auf
Funktionswerten. Diese Funktion wird auf 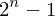 Detailkoeffizienten und einen Skalierungswert abgebildet, indem iterativ nebeneinander stehende Werte der Funktion addiert bzw. subtrahiert werden. Höhere Auflösungsstufen haben weniger Skalierungswerte und Detailkoeffizienten.
Detailkoeffizienten und einen Skalierungswert abgebildet, indem iterativ nebeneinander stehende Werte der Funktion addiert bzw. subtrahiert werden. Höhere Auflösungsstufen haben weniger Skalierungswerte und Detailkoeffizienten.
Funktionswerten. Diese Funktion wird auf Detailkoeffizienten und einen Skalierungswert abgebildet, indem iterativ nebeneinander stehende Werte der Funktion addiert bzw. subtrahiert werden. Höhere Auflösungsstufen haben weniger Skalierungswerte und Detailkoeffizienten.Flashcard set info:
Author: kread
Main topic: Informatik
Topic: Semantic Web
School / Univ.: Universität Koblenz-Landau
City: Koblenz
Published: 22.10.2010
Card tags:
All cards (35)
baum (9)
eigenschaften (1)
hs (1)
indexstruktur (1)
m-baum (2)
mehrdimensional (10)
modelle (1)
objektrelational (1)
oodbms (1)
probleme (1)
r-baum (3)
x-baum (2)
