

Funktionen von Statistik - zugehörige Teilgebiete
Funktionen:
a) Reduktion von Komplexität
b) Erkennen und Beschreiben von Strukturen und Regelmässigkeiten
->
Teilgebiete: Deskriptive Verfahren und explorative Verfahren
Funktion:
Prüfung von Hypothesen; Rückschlüsse von Stichprobeneigenschaften auf solche der Grundgesamtheit
->
Teilgebiet: Konfirmative Verfahren
Explorative Datenanalyse
• Fehlersuche und Datenbereinigung
• Charakteristika von Verteilungen (Skalenniveau, Verteilungsform)
• Analyse von Ausreisserwerten und deren Einfluss auf Verteilungen (Scatterplots, Boxplots etc.)
• Überprüfung der Qualität von Skalen (Skalenanalyse)
• Suche nach latenten Datenstrukturen (Faktorenanalyse, Clusterungstechniken, multidimensionale Skalierung)
Deskriptive Datenanalyse
• Kennwerte, welche die Charakteristika umfangreicher Verteilungen fassbar machen (Masse für die zentrale Tendenz, Homogenität bzw. Streuung, Quartilsabstände, Schiefe, Steilheit etc.)
• Kennwerte, die das Verhältnis von Merkmalsverteilungen zueinander beschreiben (Zusammenhangsmasse)
• Datenaufbereitung und visuelle Ausgabe (Barcharts, Piecharts, Scatterplots etc.)
Konfirmative Datenanalyse
• Probabilistische Rückschlüsse von Stichproben auf Grundgesamtheiten
• Testen von Hypothesen, u.a.
- zu Eigenschaften einzelner Merkmalsverteilungen (Abweichung
von theoretischen Verteilungen)
- zu Zusammenhängen zwischen zwei oder mehr
Merkmalsverteilungen
- Differenzen zwischen disjunkten Gruppen
Univariate Verfahren
• Analysen bezogen auf jeweils ein einzelnes variierendes Merkmal (eine Variable A)
• Bpeispiel
- Häufigkeitsauszählung einer Variable (Geschlecht, Alter etc.)
- Feststellen der Verteilungsform bzw. -charakteristik
- Masse für die zentrale Tendenz (z.B. Mittelwert) und die Streuung (z.B. Standardabweichung)
- Überprüfung, ob eine gegebene Verteilung einer Normalverteilung entspricht
Bivariate Verfahren
• Analysen bezogen auf jeweils zwei variierende Merkmale (zwei Variablen A und B)
• Beispiele:
- Grad der Assoziation bzw. des Zusammenhangs zwischen A und B (z.B. Produkt-Moment-Korrelation);
- Analyse von Differenzen von zwei oder mehr disjunkten Gruppen (Gruppierungsvariable B) bezüglich eines Merkmals (Variable A); (Einfaktorielle Varianzanalyse, t-Test)
Multivariate Verfahren
• Analysen bezogen auf jeweils drei oder mehr variierende
Merkmale (n Variablen A, B, C etc.)
• Bsp. für Verfahren mit einer Zielvariablen:
- Varianzanalytische Prädiktion von Variable C aufgrund der
Variablen A und B und deren Zusammenwirken (Interaktion)
- Überprüfung theoretischer Annahmen zu Einflüssen von n
Variablen (A bis N) auf Variable Y mittels multipler Regression
Beispiele für ein Verfahren ohne Zielvariable
- Analyse der Reliabilität (Messgenauigkeit) einer psychometrischen
Skala bestehend aus n Items (Einzelfragen); Skalenanalyse
Merkmale (n Variablen A, B, C etc.)
• Bsp. für Verfahren mit einer Zielvariablen:
- Varianzanalytische Prädiktion von Variable C aufgrund der
Variablen A und B und deren Zusammenwirken (Interaktion)
- Überprüfung theoretischer Annahmen zu Einflüssen von n
Variablen (A bis N) auf Variable Y mittels multipler Regression
Beispiele für ein Verfahren ohne Zielvariable
- Analyse der Reliabilität (Messgenauigkeit) einer psychometrischen
Skala bestehend aus n Items (Einzelfragen); Skalenanalyse
Multivariate statistische Analysen sind deshalb so bedeutsam,
weil...
weil...
- Die Realität, insbesondere die soziale Realität, sehr komplex ist,
- Phänomene praktisch nie nur durch eine einzige Variable
beeinflusst werden, sondern durch eine potentielle Vielzahl,
- Variablen im Abhängigkeit von anderen Variablen eine andere
Wirkung haben können (Interaktion),
- sich in zu einfachen Kausalmodellen an der Oberfläche zeigende
Zusammenhänge zu fatalen Fehlinterpretationen führen können.
Nominalskala (auch: nominales oder kategoriales Skalenniveau)
- Objekte mit identischen Merkmalsausprägungen werden zu
sogenannten Äquivalenzklassen zusammen gefasst
- Beispiele sind etwa: Gattungen von Lebewesen, Berufe, Geschlecht
Die Codierung ist willkürlich, d.h. vier Kategorien A, B, C und D können mit den Codes 1, 2, 3, 4 aber auch 3, 1, 4, 2 oder 22, 1, 245, 8174 oder w, v, x, z etc. codiert werden. Auf die Auswertungen mittels Verfahren für nominal skalierte Daten hat dies keinerlei Einfluss, da die Codes nur der Identifikation der Gruppe/Klasse dienen.
sogenannten Äquivalenzklassen zusammen gefasst
- Beispiele sind etwa: Gattungen von Lebewesen, Berufe, Geschlecht
Die Codierung ist willkürlich, d.h. vier Kategorien A, B, C und D können mit den Codes 1, 2, 3, 4 aber auch 3, 1, 4, 2 oder 22, 1, 245, 8174 oder w, v, x, z etc. codiert werden. Auf die Auswertungen mittels Verfahren für nominal skalierte Daten hat dies keinerlei Einfluss, da die Codes nur der Identifikation der Gruppe/Klasse dienen.
Ordinalskala (auch: ordinales Skalenniveau)
- Objekte werden nach Grad der Ausprägung eines Merkmals in eine Rangreihe gebracht.
- Das Kriterium der Transitivität muss erfüllt sein, d.h. wenn eine Rangfolge A, B, C, D lautet, muss neben der „Dominanz“ von A über B auch eine solche von A über C und über D bestehen.
- Beispiele sind: Windstärke in Beaufort, militärische Ränge,
Sympathierangfolge für 5 Politiker/innen
- Die Codierung ist nicht vollständig willkürlich sondern muss den
Grössenrelationen Rechnung tragen. Vier nach Rang geordnete
Klassen A, B, C, D können jedoch ebenso mit den Codes 1, 2, 3, 4 wie mit 2, 3, 4, 5, mit 10, 11, 39, 40 oder mit 1, 10, 100, 1000 codiert werden. Auf die Auswertungen mittels Verfahren für ordinal skalierte Daten hat dies keinerlei Einfluss (Äquidistanz ist nicht erforderlich).
- Das Kriterium der Transitivität muss erfüllt sein, d.h. wenn eine Rangfolge A, B, C, D lautet, muss neben der „Dominanz“ von A über B auch eine solche von A über C und über D bestehen.
- Beispiele sind: Windstärke in Beaufort, militärische Ränge,
Sympathierangfolge für 5 Politiker/innen
- Die Codierung ist nicht vollständig willkürlich sondern muss den
Grössenrelationen Rechnung tragen. Vier nach Rang geordnete
Klassen A, B, C, D können jedoch ebenso mit den Codes 1, 2, 3, 4 wie mit 2, 3, 4, 5, mit 10, 11, 39, 40 oder mit 1, 10, 100, 1000 codiert werden. Auf die Auswertungen mittels Verfahren für ordinal skalierte Daten hat dies keinerlei Einfluss (Äquidistanz ist nicht erforderlich).
Intervallskala (auch: metrisches Skalenniveau)
- Objekte werden auf einer Skala angeordnet, welche die Stärke
der Ausprägung eines Merkmals als Masszahl wiedergibt.
- Beispiele sind: Temperatur in °Celsius, Temperatur in °Fahrenheit, IQ*
- Hierfür gilt das Äquidistanzkriterium: Eine identische Distanz zwischen zwei Skalenmesswerten muss in allen Bereichen der Skala identischen Merkmalsdifferenzen
auf dem empirischen Relativ entsprechen. So muss etwa
die effektive Temperaturdifferenz zwischen den Skalenwerten 10°C und 15°C gleich gross sein wie zwischen den Skalenwerte n 22°C und 27°C.
- Die Codierung entspricht dem Messwert. Bei psychometrischen
Instrumenten wird meist das Muster 1 bis n verwendet auch wenn
lineare Transformationen (Addition, Subtraktion, Multiplikation, Division) zulässig sind und manchmal eingesetzt werden (z.B. sind die Codes 1, 2, 3, 4 oder 10, 11, 12, 13 oder 100, 110, 120, 130 äquivalent).
Ratioskala (auch: Verhältnisskalenniveau)
- Die Ratioskala entspricht einer Intervallskala mit eindeutig definiertem Nullpunkt. Dadurch gilt nicht nur Gleichheit von Distanzen sondern auch von Verhältnissen bzw. Proportionen (deshalb der Name Ratioskala). Eine Reaktionszeit von 5.6 Sekunden ist doppelt so lang wie eine Zeit von 2.8 Sekunden, eine solche von 11.2 Sekunden ist doppelt so lang wie eine Zeit von 5.6 Sekunden und viermal so lang wie eine Zeit von 2.8 Sekunden.
- Beispiele: Gewicht, Reaktionszeit, Lebensalter
- Die Codierung entspricht dem Messwert, einzig Multiplikationen und Divisionen nicht aber Additionen und Subtraktionen sind zulässig
(aber unüblich). Würde zur Variablen eine Konstante hinzugerechnet oder abgezogen ginge der Ratiocharakter der Skala verloren; sie wiese nur noch Intervallniveau auf!
- Beispiele: Gewicht, Reaktionszeit, Lebensalter
- Die Codierung entspricht dem Messwert, einzig Multiplikationen und Divisionen nicht aber Additionen und Subtraktionen sind zulässig
(aber unüblich). Würde zur Variablen eine Konstante hinzugerechnet oder abgezogen ginge der Ratiocharakter der Skala verloren; sie wiese nur noch Intervallniveau auf!
Skalenniveau - Sonderfall ordinal skalierte Variable
Ordinal skalierte Variablen mit mindestens fünf Ausprägungen können nach pragmatischen Empfehlungen von Wittenberg (1998, S. 76) dann als (quasi-) metrisch skaliert betrachtet werden, wenn die Verteilungsform weit gehend einer Normalverteilung entspricht (Normalverteilungsprüfung!).
Skalenniveau - Sonderfall - Dichotome Variablen
Dichotome Variablen, d.h. solche mit zwei natürlich gegebenen (z.B. Geschlecht) oder künstlich erzeugten Ausprägungen (z.B. Ausbildung auf Maturastufe vs. andere) können in vielen (aber nicht allen) Fällen als metrische Variablen gelten und wie solche gehandhabt werden (empfohlene Codes: „0; 1“ oder „1; 2“). (vgl. „Punkt-biseriale Korrelation“)
Skalenniveau - Sonderfall - Variablen mit Ausprägungen k >= 3
Variablen mit drei oder mehr kategorialen Ausprägungen (k ≥ 3) können in k-1 dichotome „Dummy“-Variablen transformiert werden („Dummysierung“). Jede dieser Dummy-Variablen kann wiederum als metrische Variable behandelt werden (s. nächste Veranstaltung).
Was ist eine Dummy-Variable
Eine Dummyvariable ist eine Ersatzvariable
in neuem vereinfachtem – eben dichotomem –
Format, die als Platzhalter für ein
Einzelmerkmal fungiert.

in neuem vereinfachtem – eben dichotomem –
Format, die als Platzhalter für ein
Einzelmerkmal fungiert.
Dummyvariablen in multivariaten Modellen - wieviele dürfen als Prädiktoren aufgenommen werden?
In multivariaten Modellen dürfen und sollen jeweils nur k-1 Dummyvariablen (hier zwei von dreien) eingeführt werden, da die jeweils letzte (k-te) Variable sich aus den anderen zu 100% erschliesst (lineare Abhängigkeit).
Aus einer Kategorialen Variable mit 6 Ausprägungen lassen sich also ohne Informationsverlust 3 Dummyvariablen mit zwei Ausprägungen erzeugen.
Werden diese in ein Regressionsmodell einbezogen, dürfen aber nur deren 2 als Prädiktoren aufgenommen werden.
Aus einer Kategorialen Variable mit 6 Ausprägungen lassen sich also ohne Informationsverlust 3 Dummyvariablen mit zwei Ausprägungen erzeugen.
Werden diese in ein Regressionsmodell einbezogen, dürfen aber nur deren 2 als Prädiktoren aufgenommen werden.
Was ist eine Normalverteilung?
Eine Normalverteilung ist eine bestimmte Verteilungscharakteristik bzw. eine spezifische Wahrscheinlichkeitsdichtefunktion mit grosser
Bedeutung in der Statistik.
Bedeutung in der Statistik.
Charakteristiken einer Normalverteilung
In einer Normalverteilung liegen 95.0% aller
Fälle zwischen M - Standardabweichungen
und M + Standardabweichungen.
In einer Normalverteilung liegen ca. 68% aller Beobachtungen zwischen dem Mittelwert -1 Standardabweichung und dem Mittelwert +1 Standardabweichung. Ca. 95.5% liegen zwischen M-2 Standardabweichungen und M+2 Standardabweich.

Fälle zwischen M - Standardabweichungen
und M + Standardabweichungen.
In einer Normalverteilung liegen ca. 68% aller Beobachtungen zwischen dem Mittelwert -1 Standardabweichung und dem Mittelwert +1 Standardabweichung. Ca. 95.5% liegen zwischen M-2 Standardabweichungen und M+2 Standardabweich.
Bedeutung der Normalverteilung am Beispiel des t-Tests
Sind beide Variablen annähernd normal verteilt, so ist der Flächenanteil der Überschneidungsfläche eine exakt definierte
Funktion der Mittelwertdifferenzen (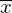 2 - 1) und mittels der z-Verteilung bestimmbar.
2 - 1) und mittels der z-Verteilung bestimmbar.

Funktion der Mittelwertdifferenzen (
2 - 1) und mittels der z-Verteilung bestimmbar.T-Test (Buch Stöckli S. 55)
Soll eine Mittelwertdifferenz mittels des t-Tests statistisch abgesichert werden, müssen beide Verteilungen annähernd normal sein.
t-Test ist eine Entscheidungsregel mit deren Hilfe ein Unterschied zwischen den empirisch gefundenen Mittelwerten zweier Gruppen näher analysiert werden kann.
H0: Differenz ist zufällig. Stichproben entstammen einer einzigen Grundgesamtheit
H1: Die Differenz ist signifikant, d.h. die beiden Stichproben entstammen nicht der gleichen Grundgesammtheit.
Er liefert eine Entscheidungshilfe dafür, ob ein gefundener
Mittelwertsunterschied rein zufällig entstanden ist, oder ob es
wirklich bedeutsame Unterschiede zwischen den zwei untersuchten
Gruppen gibt.
wichtigste Wert für die Durchführung eines t-Tests ist die
Differenz der Gruppenmittelwerte. Diese Differenz bildet den
Stichprobenkennwert des t-Tests (Mittelwert 1 - Mittelwert 2) T-Test kann nur zwei Mittelwerte vergleichen
t-Test ist eine Entscheidungsregel mit deren Hilfe ein Unterschied zwischen den empirisch gefundenen Mittelwerten zweier Gruppen näher analysiert werden kann.
H0: Differenz ist zufällig. Stichproben entstammen einer einzigen Grundgesamtheit
H1: Die Differenz ist signifikant, d.h. die beiden Stichproben entstammen nicht der gleichen Grundgesammtheit.
Er liefert eine Entscheidungshilfe dafür, ob ein gefundener
Mittelwertsunterschied rein zufällig entstanden ist, oder ob es
wirklich bedeutsame Unterschiede zwischen den zwei untersuchten
Gruppen gibt.
wichtigste Wert für die Durchführung eines t-Tests ist die
Differenz der Gruppenmittelwerte. Diese Differenz bildet den
Stichprobenkennwert des t-Tests (Mittelwert 1 - Mittelwert 2) T-Test kann nur zwei Mittelwerte vergleichen
Normalverteilung - Bedeutung und Eigenschaften
Ist eine der Variablen, oder beide, nicht annähernd normalverteilt,
ist der Flächenanteil des Überschneidungsbereichs für bestimmte
Mittelwertdifferenzen nicht mehr exakt mittels der z-Verteilung ableitbar.
Es sind keine verlässlichen, wahrscheinlichkeitstheoretisch begründeten Aussagen zur Signifikanz von Mittelwertdifferenzen mehr möglich.
ist der Flächenanteil des Überschneidungsbereichs für bestimmte
Mittelwertdifferenzen nicht mehr exakt mittels der z-Verteilung ableitbar.
Es sind keine verlässlichen, wahrscheinlichkeitstheoretisch begründeten Aussagen zur Signifikanz von Mittelwertdifferenzen mehr möglich.
