

Was sind die methodischen Zugänge nach W. Stern im Überblick?
Systematik (theoretisch-methodische Zugänge)

- Variationsforschung: Eine Merkmalsvarianz wird an vielen Personen(‐gruppen) untersucht, z.B. Anlage/Umweltforschung; Geschlechtsunterschiede
- Korrelationsforschung: 2 oder mehrere Merkmale an vielen Personen (z.B. faktorenanalytische Intelligenzforschung)
- Psychographie: Eine Person in Bezug auf viele Merkmale; z.B. Interpretationen eines Persönlichkeitsprofils in der psychologischen Diagnostik)
- Komparationsforschung: Zwei oder mehrere Personen in Bezug auf viele Merkmale; z.B. Einsatz von Typisierungsverfahren um Risikogruppen aufzufinden)
Tags: Methoden, Stern
Source: S12
Source: S12
Was sind die 5 Hauptfragestellungen der differentiellen Psychologie im Überblick?
Vier Hauptfragestellungen aus Systematik nach Stern und Methodenentwicklung:
- Variationsforschung
- Korrelationsforschung
- Psychographie
- Komparationsforschung
- Differentiell‐psychologische Methodenentwicklung
Tags: differentielle Psychologie, Komparationsforschung, Korrelationsforschung, Methoden, Psychographie, Variationsforschung
Source: VO02
Source: VO02
Was kennzeichnet ein Experiment? Wie ist der Ablauf eines Experiments?
Was ist ein Quasi-Experiment?
Was ist ein Quasi-Experiment?
Experiment:

Quasi‐Experiment:
- Studium von Phänomenen (abhängige Variable, AV; z.B. Konzentrationsleistung) unter kontrollierten Bedingungen, wobei die Untersuchungseinheit (meist Vpn) den unabhängigen Variablen (UV = Versuchsbedingungen oder Treatments; z.B. verschiedene Abstufungen von Lärmbelastung) randomisiert (= zufällig) zugewiesen werden.
- Bedeutung: Nur nach Durchführung eines Experiments ist eine kausale Ergebnisinterpretation möglich.
Quasi‐Experiment:
- Studium von Phänomenen (AV) unter kontrollierten Bedingungen, wobei die Untersuchungseinheiten (Vpn) den UV nicht randomisiert zugewiesen werden (können), sondern die UV eine Auswahl aus „vorgegebenen Gruppenzugehörigkeiten“ darstellen (z.B. Patientengruppen mit unterschiedlicherDiagnose, Geschlecht etc. - Subjektvariable).
- Nach Durchführung eines Quasi‐Experiments ist keine Kausalinterpretation der Ergebnisse möglich.
Tags: Experiment, Methoden
Source: S31, VO04
Source: S31, VO04
Was versteht man unter Varianz?
Die Varianz (s²) ist ein Maß für die Verschiedenheit (Variabilität) von Messwerten eines Merkmals in einer Stichprobe.
s² wird umso größer, je mehr die Messwerte vom gemeinsamen Mittelwert abweichen, also je unterschiedlicher die Messwerte sind.

s² = „mittleres Abweichungsquadrat“ (Varianz)
Wurzel aus s² = Standardabweichung (s)
n = Stichprobenumfang
i = Laufindex (i = 1, 2, …, i, … n)
xi = Messwerte
x quer = Mittelwert (Durchschnitt)
s² wird umso größer, je mehr die Messwerte vom gemeinsamen Mittelwert abweichen, also je unterschiedlicher die Messwerte sind.
s² = „mittleres Abweichungsquadrat“ (Varianz)
Wurzel aus s² = Standardabweichung (s)
n = Stichprobenumfang
i = Laufindex (i = 1, 2, …, i, … n)
xi = Messwerte
x quer = Mittelwert (Durchschnitt)
Tags: Methoden, Varianz
Source: S32
Source: S32
Was versteht man unter Korrelation?
Pearson Korrelation: Der Korrelationskoeffizient r ist ein Maß für die Stärke eines linearen Zusammenhangs zwischen 2 Variablen (X und Y).

Zähler: „mittleres Abweichungsprodukt“ (Kovarianz, Cov)
Nenner: Produkt der Standardabweichungen
Es gilt: ‐1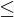 r +1 und 0 |r| 1
r +1 und 0 |r| 1
Also: Maximaler (linearer) Zusammenhang bei r = +1 (gleichsinnig) und r = -1 (gegenläufig);
bei r=0 kein Zusammenhang

Beachte:
nicht‐lineare Zusammenhänge (siehe Abb.) werden durch r nicht adäquat abgebildet
Zähler: „mittleres Abweichungsprodukt“ (Kovarianz, Cov)
Nenner: Produkt der Standardabweichungen
Es gilt: ‐1
r +1 und 0 |r| 1Also: Maximaler (linearer) Zusammenhang bei r = +1 (gleichsinnig) und r = -1 (gegenläufig);
bei r=0 kein Zusammenhang
Beachte:
nicht‐lineare Zusammenhänge (siehe Abb.) werden durch r nicht adäquat abgebildet
Tags: Korrelation, Methoden
Source: S32
Source: S32
Was ist bei der Interpretation einer Korrelation zu beachten?
Eine dem Betrag nach hohe (signifikante) Korrelation darf nicht kausal (d.h. im Sinne einer „wenn – dann“ Beziehung) interpretiert werden, weil unklar ist was zutrifft:
(1) X beeinflusst Y kausal,
(2) Y beeinflusst X kausal,
(3) X und Y werden von einer dritten oder mehreren weiteren Variablen kausal beeinflusst,
(4) X und Y beeinflussen sich wechselseitig kausal.

Bortz (1989, S.288):
Eine Korrelation zwischen zwei Variablen ist eine notwendige, aber keine hinreichende Voraussetzung für kausale Abhängigkeiten.
Korrelationen sind deshalb nur als Koinzidenzen zu interpretieren; sie liefern jedoch Hinweise für mögliche kausale Beziehungen, die dann in sorgfältig kontrollierten Experimenten überprüft werden können.
Bei einer korrelationsstatistischen Überprüfung von Zusammenhangshypothsen ist es besonders wichtig, dass die Stichprobe tatsächlich die gesamte Population repräsentiert, für die das Untersuchungsergebnis gelten soll. Ist das nicht der Fall, kann es zu drastischen Verzerrungen der Korelation kommen und damit zu falschen Schlussfolgerungen (Korrelationen sind "stichprobenabhängig").
Beispiel: „wahre“ Korrelation zwischen Schulleistung und Intelligenz (bzw. IQ) beträgt in der Population alles Schüler ρ (sprich: „rho“) = 0.71 [griechischer Buchstabe für Populationsschätzer]
Die Abbildungen zeigen, wie sich dieser "wahre" Zusammenhang bei Stichprobenselektion ändern kann:

(1) X beeinflusst Y kausal,
(2) Y beeinflusst X kausal,
(3) X und Y werden von einer dritten oder mehreren weiteren Variablen kausal beeinflusst,
(4) X und Y beeinflussen sich wechselseitig kausal.
Bortz (1989, S.288):
Eine Korrelation zwischen zwei Variablen ist eine notwendige, aber keine hinreichende Voraussetzung für kausale Abhängigkeiten.
Korrelationen sind deshalb nur als Koinzidenzen zu interpretieren; sie liefern jedoch Hinweise für mögliche kausale Beziehungen, die dann in sorgfältig kontrollierten Experimenten überprüft werden können.
Bei einer korrelationsstatistischen Überprüfung von Zusammenhangshypothsen ist es besonders wichtig, dass die Stichprobe tatsächlich die gesamte Population repräsentiert, für die das Untersuchungsergebnis gelten soll. Ist das nicht der Fall, kann es zu drastischen Verzerrungen der Korelation kommen und damit zu falschen Schlussfolgerungen (Korrelationen sind "stichprobenabhängig").
Beispiel: „wahre“ Korrelation zwischen Schulleistung und Intelligenz (bzw. IQ) beträgt in der Population alles Schüler ρ (sprich: „rho“) = 0.71 [griechischer Buchstabe für Populationsschätzer]
Die Abbildungen zeigen, wie sich dieser "wahre" Zusammenhang bei Stichprobenselektion ändern kann:
Tags: Korrelation, Methoden
Source: S32
Source: S32
Was ist das Prinzip der Varianzzerlegung?
Prinzip ist interessant, weil es zeigt, wie in der Differentiellen Psychologie Kausalzusammenhänge untersucht werden können.
Zentrale Frage: Welcher Anteil der Gesamtvarianz eines
Phänomens wird durch die Varianzen der einzelnen an ihm
beteiligten Komponenten „erklärt“ - Bestimmung von
Varianzanteilen.
Dazu ein Beispiel (Hofstätter, 1977)
Weitere Komponenten (z.B. Knochenstärke) bleiben aus Vereinfachungsgründen hier unberücksichtigt.

Die Gesamtvarianz s² (kg) ist (unter Annahme, dass kh und kf unabhängig voneinander variieren) in zwei additive Komponenten (Varianzanteile) zerlegbar:
s²(kg) = s²(kg|kf) + s²(kg|kh)
100% = X% + Y%
s²(kg|kf) = Varianz des Gewichts aufgrund der Körperfülle.

Ergebnis könnte lauten:
48% von s²(kg) sind durch Körperhöhe “bedingt”,
52% durch Körperfülle (und andere Komponenten)
Analog dazu können Anlage‐ und Umweltvarianzanteile an der Gesamtvarianz eines Merkmals „M“ geschätzt werden:
s²(M) = s²(M|A) + s²(M|U) (Zwillingsforschung)
(Voraussetzungen: Kein Zusammenhang zwischen den beiden Varianzanteilen [d.h. r(A, U) = 0] und fehlerfreie Erfassung des Merkmals „M“.)
Zentrale Frage: Welcher Anteil der Gesamtvarianz eines
Phänomens wird durch die Varianzen der einzelnen an ihm
beteiligten Komponenten „erklärt“ - Bestimmung von
Varianzanteilen.
Dazu ein Beispiel (Hofstätter, 1977)
Weitere Komponenten (z.B. Knochenstärke) bleiben aus Vereinfachungsgründen hier unberücksichtigt.
Die Gesamtvarianz s² (kg) ist (unter Annahme, dass kh und kf unabhängig voneinander variieren) in zwei additive Komponenten (Varianzanteile) zerlegbar:
s²(kg) = s²(kg|kf) + s²(kg|kh)
100% = X% + Y%
s²(kg|kf) = Varianz des Gewichts aufgrund der Körperfülle.
Ergebnis könnte lauten:
48% von s²(kg) sind durch Körperhöhe “bedingt”,
52% durch Körperfülle (und andere Komponenten)
Analog dazu können Anlage‐ und Umweltvarianzanteile an der Gesamtvarianz eines Merkmals „M“ geschätzt werden:
s²(M) = s²(M|A) + s²(M|U) (Zwillingsforschung)
(Voraussetzungen: Kein Zusammenhang zwischen den beiden Varianzanteilen [d.h. r(A, U) = 0] und fehlerfreie Erfassung des Merkmals „M“.)
Tags: Methoden, Varianz, Varianzzerlegung, Zwillingsmethode
Source: S34
Source: S34
Welche Konsequenzen haben Regressionseffekte für quasiexperimentelle Untersuchungen zur Prüfung von Veränderungshypothesen?
Beispiel - Fragestellung: Wie wirkt ein Programm zur kognitiven Frühförderung bei Oberschichtkindern (OKi) bzw. bei Unterschichtkindern (UKi)?
Hilft es beiden Gruppen in gleicher Weise?
Untersuchungsdesign: Pretest (Vortests) - Fördermaßnahme - Posttest.
Annahme: Das Merkmal „kognitive Fähigkeit“ sei in der Population der OKi und in der Population der UKi normalverteilt.
Messung des Merkmals: Zweimalige Durchführung eines Tests (Paralleltestversionen). Die Reliabilität der Tests ist nicht vollkommen (wie in Psychologie üblich).
Studie 1: Interpretation korrekt! (links)
Studie 2: Interpretation falsch! (rechts)

Hilft es beiden Gruppen in gleicher Weise?
Untersuchungsdesign: Pretest (Vortests) - Fördermaßnahme - Posttest.
Annahme: Das Merkmal „kognitive Fähigkeit“ sei in der Population der OKi und in der Population der UKi normalverteilt.
Messung des Merkmals: Zweimalige Durchführung eines Tests (Paralleltestversionen). Die Reliabilität der Tests ist nicht vollkommen (wie in Psychologie üblich).
Studie 1: Interpretation korrekt! (links)
- 2 Zufallsstichproben aus Populationen gezogen
- Vortestergebnis (t1): kognitive Fähigkeit bei OKi weiter entwickelt ist als bei UKi.
- Posttestergebnis (t2): keine sign. Änderungen (weder bei OKi noch bei UKi) - Förderprogramm hat keine Wirkung.
- Interpretation korrekt, weil Regressionseffekte hier ausgeschlossen sind (repräsentative Stichproben).
Studie 2: Interpretation falsch! (rechts)
- OKi und UKi werden anhand von Vortestergebnissen parallelisiert - Mittelwerte von OKi und UKi zu t1 annähernd gleich.
- Parallelisierung führt jedoch dazu, dass aus Oberschicht überwiegend unterdurchschnittliche Kinder in Stichprobe aufgenommen werden, aus Unterschicht überwiegend überdurchschnittliche.
- Wieder sei das Förderprogramm wirkungslos.
- Dennoch zu t2 ein Unterschied, weil beide Stichproben zum Mittelwert ihrer Referenzpopulation hin regredieren.
Tags: Methoden, Quasi-Experiment, Regression
Source: S37
Source: S37
Erkläre anhand eines Gedankenexperiments die Idee der Faktorenanalyse?
Datenerhebung an n Vpn mit k = 5 Messinstrumenten (Variable):
Beobachtung in der Interkorrelationsmatrix (k x k): 3 Variable (Thermometer) sind hoch korreliert (|r| → 1.0), ebenso die beiden anderen (Puls). Zwischen Variablen, entnommen aus jeweils einer Variablengruppe, liegen jedoch nur niedrige Korrelationen vor (|r| → 0.0).
FA wird durchgeführt; Fragestellung: Wie viele unabhängige Faktoren (Dimensionen, Eigenschaften, Konstrukte) sind (minimal) notwendig, um die Zusammenhänge in den fünf Variablen zu „erklären“?
Ergebnis (Gedankenexperiment): Die Daten können durch 2 Faktoren „erklärt“ werden.
Auf 1. Faktor „laden“ 3 Variable (Thermometer) hoch [d.h. sind mit dem Faktor hoch korreliert], auf 2. Faktor laden die Pulsmessungen hoch.
Allgemein: m Faktoren, wobei m < k - FA dient der Informationsverdichtung!
Interpretation: Die fünf Messinstrumente messen nur 2 unabhängige Dimensionen (Eigenschaften, Faktoren). Drei etablieren den 1. Faktor, zwei den 2. Faktor. Weil wir wissen, was die Messinstrumente messen ist hier die inhaltliche Interpretation leicht - Körpertemperatur (Fakt.1) und
Herzschläge/min (Fakt.2).
Folgerung: Zukünftig wird es nicht mehr notwendig sein, alle fünf Messinstrumente zu verwenden; eines für Faktor 1 und ein zweites für Faktor 2 werden genügen. (Stichworte: Datenverdichtung und Datenreduktion als Ziel der FA)
Beachte: Hätten wir ein Hygrometer hinzugenommen, wäre ein dritter Faktor (Luftfeuchtigkeit) resultiert. - Es können also nur jene Eigenschaften faktorenanalytisch gewonnen (=extrahiert) werden, die in den in den Analysen aufgenommenen Variablen enthalten sind.
- 3 Thermometer (mit verschiedenen Skalen: Kelvin, Fahrenheit, Celsius)
- 2 Pulsmessungen (durch Arzt / mittels Pulsmessgerät)
Beobachtung in der Interkorrelationsmatrix (k x k): 3 Variable (Thermometer) sind hoch korreliert (|r| → 1.0), ebenso die beiden anderen (Puls). Zwischen Variablen, entnommen aus jeweils einer Variablengruppe, liegen jedoch nur niedrige Korrelationen vor (|r| → 0.0).
FA wird durchgeführt; Fragestellung: Wie viele unabhängige Faktoren (Dimensionen, Eigenschaften, Konstrukte) sind (minimal) notwendig, um die Zusammenhänge in den fünf Variablen zu „erklären“?
Ergebnis (Gedankenexperiment): Die Daten können durch 2 Faktoren „erklärt“ werden.
Auf 1. Faktor „laden“ 3 Variable (Thermometer) hoch [d.h. sind mit dem Faktor hoch korreliert], auf 2. Faktor laden die Pulsmessungen hoch.
Allgemein: m Faktoren, wobei m < k - FA dient der Informationsverdichtung!
Interpretation: Die fünf Messinstrumente messen nur 2 unabhängige Dimensionen (Eigenschaften, Faktoren). Drei etablieren den 1. Faktor, zwei den 2. Faktor. Weil wir wissen, was die Messinstrumente messen ist hier die inhaltliche Interpretation leicht - Körpertemperatur (Fakt.1) und
Herzschläge/min (Fakt.2).
Folgerung: Zukünftig wird es nicht mehr notwendig sein, alle fünf Messinstrumente zu verwenden; eines für Faktor 1 und ein zweites für Faktor 2 werden genügen. (Stichworte: Datenverdichtung und Datenreduktion als Ziel der FA)
Beachte: Hätten wir ein Hygrometer hinzugenommen, wäre ein dritter Faktor (Luftfeuchtigkeit) resultiert. - Es können also nur jene Eigenschaften faktorenanalytisch gewonnen (=extrahiert) werden, die in den in den Analysen aufgenommenen Variablen enthalten sind.
Tags: Faktorenanalyse, Methoden
Source: S38
Source: S38
Was ist die Ziel bzw. die Idee der Faktorenanalyse?
Die Faktorenanalyse (FA) ist ein Verfahren zur Informationsverdichtung (wissenschaftliche Ökonomisierung) mit dem Ziel, die, einem Variablensatz (= manifeste Variable) zugrunde liegende Dimensionen (=latente Variable bzw. Konstrukte, Faktoren, Eigenschaften) rechnerisch zu ermitteln.
Ausgangspunkt sind die standardisierten Variablen und deren Interkorrelationen (Korrelationen zwischen allen Paaren von Variablen). FA versucht die (linearen) Zusammenhänge (Interkorrelationen), die zwischen Variablen bestehen, einfacher zu erklären, indem diese Zusammenhänge auf wenige gemeinsame Faktoren zurückgeführt werden.

Ausgangspunkt sind die standardisierten Variablen und deren Interkorrelationen (Korrelationen zwischen allen Paaren von Variablen). FA versucht die (linearen) Zusammenhänge (Interkorrelationen), die zwischen Variablen bestehen, einfacher zu erklären, indem diese Zusammenhänge auf wenige gemeinsame Faktoren zurückgeführt werden.
Tags: Faktorenanalyse, Methoden
Source: S38
Source: S38
Wie ist die Vorgehensweise bei der Faktorenanalyse?

Standardisierung der Ausgangsdaten
Variable, die in FA eingehen, haben unterschiedlich große Varianzen s² bzw.
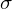 ² (Populationsschätzer).
² (Populationsschätzer).Da für die k Variable Varianzanteile bestimmt werden sollen, die sich durch m gemeinsame Faktoren erklären lassen, müssen zunächst die s2 „vereinheitlicht“ werden.
Das geschieht ohne Informationsverlust (Korrelationen sind invariant gegenüber linearer Messwerttransformation) durch Standardisierung jeder Variable:

Korrelationsmatrix
Die Korrelationen zwischen je zwei standardisierten Variablen seien durch „Überlappungsbereiche“ dargestellt:

Für jede Variable ergibt sich ein „Geflecht“ von Überlappungen und jeweils einem variablespezifischen, eigenständigen Bereich („uniqueness“).
FA soll dieses „Geflecht“ einfacher strukturieren, also „Gemeinsames“ von „Speziellem“ trennen.
Die Faktoren werden üblicherweise so bestimmt, dass sie miteinander nicht korreliert sind (= „orthogonale“ Faktoren).
Der 1. Faktor soll größtmögliche Überlappungen aller Variablen „umfassen“, dann 2. Faktor … usw.
Beispiel für zwei Variable:

Diesen Varianzanteilen entsprechen sog. Ladungszahlen
aij² = Varianzanteil des j‐ten Faktors an Variable Xi ; oder Ausmaß, in dem die Variable Xi mit dem latenten Faktor Fj zusammenhängt). [aij² - zu interpretieren wie Korrelationen mit Werten zwischen ‐1 und +1]
Ziel ist die Berechnung der Faktorenladungsmatrix (k Var., m Fakt., mit m < k):
Aus den der Größe nach geordneten Ladungszahlen kann auf die inhaltliche Interpretation des jeweiligen Faktors rückgeschlossen werden.
Überlegung: Werden genau so viele Faktoren „extrahiert“ wie Variable einbezogen wurden, dann kann zwar 100% der „Gesamtvarianz“ (= k) durch die Faktoren erklärt werden, aber eine Informationsverdichtung hat nicht stattgefunden (daher Forderung: m < k).
Methode = Extremwertaufgabe mit der Idee, dass möglichst
wenige Faktoren möglichst viel der Gesamtvarianz erklären.
Lösung führt zu Eigenwertproblem, das in numerischer
Statistik bekannt ist (iteratives Vorgehen zur Schätzung
der Ladungen).
Tags: Faktorenanalyse, Methoden
Source: S40
Source: S40
Was sind die Prinzipien der Faktorenanalyse?
Die m gemeinsamen Faktoren werden so bestimmt, dass …
- … der durch sie erklärte Varianzanteil maximal ist;
- … sie statistisch unkorreliert sind (orthogonal);
- … sie Einfachstruktur (simple structure) aufweisen, d.h. nach Rotation des Achstensystems, soll jeder Faktor in einigen Variablen hohe Ladungen und sonst vorwiegend Null‐Ladungen aufweisen - das dient der besseren Interpretierbarkeit: die Variablen mit hohen Ladungen (= Markervariablen) „beschreiben“ (determinieren) inhaltlich den Faktor
Tags: Faktorenanalyse, Methoden
Source: S40
Source: S40
Was sollte das Modell der FA nicht auf die Daten angewandt werden?
Werden gleich viele Faktoren "extrahiert" wie Variablen in der Analyse aufgenommen wurden, dann kann zwar die "Gesamtvarianz" durch die Faktoren erklärt werden, aber eine Informationsverdichtung hat nicht stattgefunden.
Also ist zu fordern, dass die Anzahl der Faktoren (m) kleiner sein soll als die Anzahl der in die Analyse einbezogenen Variablen (k), also: m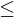 k.
k.
Bei beispielsweise k=11 Variablen beträgt die Gesamtvarianz²ges = k = 11, weil die Variablen standardisiert sind und jeweils ² = 1 beitragen. Diese Überlegung ist insofern interesant, als bei der Interpretation faktorenanalytischer Ergebnisse meist gesagt wird, wie viel Prozent der Gesamtvarianz durch die extrahierten Faktoren erklärt wird.
Ist dieser Prozentsatz erklärter Gesamtvarianz gering (Faustregel: z.B. kleiner als 60%), dann sollte das Modell der FA auf diese Daten besser nicht angewandt werden.
Also ist zu fordern, dass die Anzahl der Faktoren (m) kleiner sein soll als die Anzahl der in die Analyse einbezogenen Variablen (k), also: m
k.Bei beispielsweise k=11 Variablen beträgt die Gesamtvarianz
²ges = k = 11, weil die Variablen standardisiert sind und jeweils ² = 1 beitragen. Diese Überlegung ist insofern interesant, als bei der Interpretation faktorenanalytischer Ergebnisse meist gesagt wird, wie viel Prozent der Gesamtvarianz durch die extrahierten Faktoren erklärt wird.Ist dieser Prozentsatz erklärter Gesamtvarianz gering (Faustregel: z.B. kleiner als 60%), dann sollte das Modell der FA auf diese Daten besser nicht angewandt werden.
Tags: Faktorenanalyse, Methoden, Varianz
Source: S40
Source: S40
Was ist das multiple FA-Modell?
von Garnett, 1919; weiterentwickelt von Thurstone, 1931, 1935

F1, F2, ... Fm - "common factors" (latente Eigenschaften)
Si - spezifische Faktoren des Tests Xi
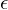 i - Fehlerterm des Tests Xi
i - Fehlerterm des Tests Xi
Die Ladungszahlen aij (bzw. deren Quadrat) können auf drei verschiedene Arten interpretiert werden:
F1, F2, ... Fm - "common factors" (latente Eigenschaften)
Si - spezifische Faktoren des Tests Xi
i - Fehlerterm des Tests XiDie Ladungszahlen aij (bzw. deren Quadrat) können auf drei verschiedene Arten interpretiert werden:
- aij = Gewicht des Faktors Fj für die Variabe Xi
- aij = Korrelation des Faktors Fj mit der Variable Xi
- aij² = Varianzanteil der i-ten Variable, der durch den Faktor erklärt wird
Tags: Faktorenanalyse, Methoden
Source: S40
Source: S40
Welche zwei Typen der Faktorenanalyse können unterschieden werden?
Exploratorisch (hypothesenerkundend)
Exploratorische FA soll latente Faktorenstruktur einer Menge korrelierender Variablen „erkunden“. Spezielles Vorwissen (z.B. zur Anzahl von Faktoren) besteht nicht. Das Vorgehen ist also deskriptiv.
Konfirmatorisch (hypothesenprüfend)
Konfirmatorische FA hat zum Ziel, eine apriori bestehende Faktorenstruktur (z.B. aus Literatur bekannt) auf Verträglichkeit mit neuen empirischen Daten zu prüfen.
Das Vorgehen ist Hypothesen geleitet, inferenzstatistische Schlussfolgerungen sind möglich.
Anmerkung: Auch die konfirmatorische FA sagt nichts darüber aus, ob eine gefundene Faktorenstruktur auch die einzige gültige Struktur darstellt.
Exploratorische FA soll latente Faktorenstruktur einer Menge korrelierender Variablen „erkunden“. Spezielles Vorwissen (z.B. zur Anzahl von Faktoren) besteht nicht. Das Vorgehen ist also deskriptiv.
Konfirmatorisch (hypothesenprüfend)
Konfirmatorische FA hat zum Ziel, eine apriori bestehende Faktorenstruktur (z.B. aus Literatur bekannt) auf Verträglichkeit mit neuen empirischen Daten zu prüfen.
Das Vorgehen ist Hypothesen geleitet, inferenzstatistische Schlussfolgerungen sind möglich.
Anmerkung: Auch die konfirmatorische FA sagt nichts darüber aus, ob eine gefundene Faktorenstruktur auch die einzige gültige Struktur darstellt.
Tags: Faktorenanalyse, Methoden
Source: S41
Source: S41
Welche Probleme des Messens gibt es in Sozialwissenschaften? Wodurch kann das Problem tlw. überwunden werden?
Probleme des Messens latenter Eigenschaften:
Was und wie soll da noch "gemessen" werden ?
Die Item Response Theorie kann zwar nicht alle, aber zentrale Problem des Messens in den Sozialwissenschaften überwinden. IRT‐basierte Tests haben daher große Vorteile (hinsichtlich Präzision der Messung) gegenüber Klassische-Testtheorie‐basierten Testverfahren;
ihr Nachteil: sie sind viel aufwändiger zu entwickeln.
- Zu messende Eigenschaft (latente Dimension) ist unbekannt; sie wird postuliert (z.B. Intelligenz)
- Unbekannt ist, welche Messinstrumente (Testaufgaben, Items) zur Erfassung der latenten Dimension geeignet sind
- Schwierigkeitsgrade der Items sind unbekannt
- Fähigkeitsgrade der Personen sind unbekannt
- Bei Fähigkeitstest oftmals Beschränkung auf dichotome Items (gelöst / nicht gelöst)
Was und wie soll da noch "gemessen" werden ?
Die Item Response Theorie kann zwar nicht alle, aber zentrale Problem des Messens in den Sozialwissenschaften überwinden. IRT‐basierte Tests haben daher große Vorteile (hinsichtlich Präzision der Messung) gegenüber Klassische-Testtheorie‐basierten Testverfahren;
ihr Nachteil: sie sind viel aufwändiger zu entwickeln.
Tags: Item Response Theorie, Methoden
Source: S42
Source: S42
Was sind die Gemeinsamkeiten bzw. Unterschiede zwischen KTT und IRT?
KTT = klassische Testtheorie (seit etwa 1920)
IRT = Item-Response Theorie (Anfänge seit 1960)
Gemeinsamkeiten: Beide Testtheorien gehen von der Annahmen einer latenten Dimension aus (Konstrukt, das gemessen werden soll).
Unterschiede der Testtheorien bezüglich Test‐(Skalen‐)konstruktion
IRT = Item-Response Theorie (Anfänge seit 1960)
Gemeinsamkeiten: Beide Testtheorien gehen von der Annahmen einer latenten Dimension aus (Konstrukt, das gemessen werden soll).
Unterschiede der Testtheorien bezüglich Test‐(Skalen‐)konstruktion
| Klassische Testtheorie | Item Response Theorie |
| Ansatz bei Testrohwerten (=Anzahl gelöster Aufgaben): Die Frage, ob alle Testitems zur Erfassung der latenten Dimension geeignet sind, wird nicht thematisiert. | Ansatz bei Einzelitems: Die Überprüfung, ob alle Items dieselbe latenten Dimension erfassen ist zentral und kann mit dem RM durchgeführt werden (d.h. Frage nach Eindimensionalität bzw. Homogenität der Testaufgaben ist empirisch prüfbar). |
| Beobachtbares Verhalten (d.h. die von Vpn erzielten Testscores od. Rohwerte) werden gleichgesetzt mit „Messung“ der latenten Dimension (deterministisch); das ist nachweislich oft nicht korrekt. | Beobachtbares Verhalten (ob eine Vp ein einzelnes Item löst oder nicht löst) gilt nur als Symptom (Indikator) für die latenten Dimension (probabilistisch). Die Wahrscheinlichkeit, ein bestimmtes Items zu lösen, wird durch ein mathematisches Modell (z.B. Rasch Modell) spezifiziert. |
| Empirische Prüfbarkeit der Modellannahmen ist nicht möglich (Modelltests fehlen). | Empirische Prüfbarkeit der Modellannahmen ist im möglich (mittels sog. Modelltests). |
Tags: Item Response Theorie, Methoden, Test
Source: S42
Source: S42
Wie kann die Messung der Konstrukte in der humanistischen Persönlichkeitstheorie erfolgen?
Messung der Konstrukte mittels verschiedener Techniken:
- Q‐Sort (Question Sort; Methode stammt von Stephenson, 1953): Kärtchen mit Selbstbeschreibungen (Statements) werden vorgegebenen Zustimmungskategorien zugeordnet. ↔ Gegensatz zur klass. Fragebogen‐Technik, in der Ausprägungsgrade den Statements (durch Ankreuzen) zugeordnet werden.- Testleiter kann eine bestimmte Verteilung der Kärtchen über die einzelnen Kategorien vorgegeben (z.B. NV, Gleichverteilung), um etwa zu „provozieren“, daß auch die Randbereiche der Skala verwendet werden.- Die Tpn können ihre bereits getroffenen Zuordnungsentscheidungen jederzeit revidieren (entfall des „Juroren‐ Dilemmas“).
- Adjektivlisten: Hier sucht die Vpn jene Adjektive aus einer vorgegebenen Adjektivliste heraus, die auf sie besonders zutreffen.
- Semantisches Differential (Osgood, 1953): Einschätzung von Begriffen (z.B. „Mein Selbstbild“ oder „Mein Idealbild“) auf vorgegebenen Skalen adjektivischer Gegensatzpaare.Rogers wandte diese Technik an, um Diskrepanzen zwischen Real‐Selbst und Ideal‐Selbst quantifizieren zu können.
- Fragebogen zu Selbstaktualisierungstendenz (von Jones & Crandall, 1986): Beispielitems (aus Pervin, 1993, S. 205):- „Es ist immer notwendig, dass andere das bestätigen, was ich tue“ (‐)- „Ich befürchte immer, einer Situation nicht gewachsen zu sein“ (‐)- „Ich schäme mich wegen keines meiner Gefühle“ (+)- „Ich glaube, dass Menschen im Innersten gut sind und dass man ihnen vertrauen kann“(+)
Tags: humanistische Persönlichkeitstheorie, Methoden, Rogers
Source: S138
Source: S138
Wie erfolgt die Messung des R/S Konstrukts?
Messung des R/S Konstrukts:
- Experimentell (Wortassoziationstest): Nach Byrne et al. (1962) war Reliabilität gering.
- Daher: Entwicklung eines Fragebogens (Byrne et al. 1963). Die neue R/S-Skala war zufriedenstellend reliabel und valide (deutsche Bearbeitung von Krohne, 1974). Aus 127 Items des MMPI (Minnesota Multiphasic Personality Inventory) wurde eine R/S-Skala unter der Annahme konstrukiert, das - Represser hohe Werte auf der Hysterie- und Lügen-Skala aufweisen und - Sensitizer hohe Werte in den Skalen Depression, Psychasthenie und Angst.Die neue R/S-Skala war zufriedenstellend reliabel und valide.
Tags: Methoden, R/S Konstrukt
Source: S144
Source: S144
Welche Datengewinnungsmethoden werden in der Anlagen/Umweltforschung verwendet?
- Stammbaumanalysen: Nur mehr historisch interessant. Retrospektive Betrachtung der Häufung von besonderen Begabungen (sog. Merkmalsträger) oder Minderbegabung als Funktion des Verwandtschaftsgrades in Familien- Galton (1869): untersuchte 100 Familien von berühmten Mathematikern und Naturwissenschaftlern- Juda (ca 1940): untersuchte 113 Künstler- und 181 Wissenschafterfamilien im deutschsprachigen Raum (z.B. Bernoulli, Bach, ...) - Hochbegabung treten gehäuft auf.- Reed (1965): Kinder von geistig retardierten Personen waren zu 50,7% wieder geistig retardiert. Mit Abnahme des Verwandtschaftsgrades nahm der Prozentsatz intellektuell retardierter Nachkommen ab.Kritik: Häufung in den Familien zwar gegeben, aber keine Beweise für Vererbarkeit, weil Anlage- und Umwelteinflüsse dabei eine Rolle Spielen. Eine konklusive Ergebnisinterpretation ist daher nicht möglich.
- Studien an Heimkindern: Nichtverwandte Pflege- und Heimkinder, die gemeinsam aufwachsen, würden aufgrund der gleichartigen Umweltbedingungen ähnlicher sein als zufällig aus der Population heraus gegriffene Kinder.Kritik: Die notwendige Voraussetzung für eine konklusive Interpretation, dass Pflegekinder hinsichtlich ihres Genotyps (ebenso wie die Vergleichsstichprobe) eine Zufallsstichprobe darstellen, ist nicht plausibel.
- Adoptionsstudien: Die Ähnlichkeiten (Ä) von Adoptivkindern zu ihren Adoptiveltern (genetische Ä = 0%) vs. leiblichen Eltern (genetische Ä = 50%) werden analysiert.Probleme: - Vollständigkeit und Zuverlässigkeit der Daten (leiblicher Vater oft ungewiss). - Umweltvarianz in Adoptivfamilien eingeschränkt.- Eltern, die ein Kind zur Adoption freigeben, sind wahrscheinlich keine Zufallsauswahl aus der Population.
- Zwillingsstudien - Eineiige Zwillinge (EZ) haben identische genetische Ausstattung.- Zweieiige Zwillinge (ZZ) sind Geschwister gleichen Alters. - Getrennt oder gemeinsam aufgewachsen?
Tags: Anlage/Umwelt, Methoden
Source: S146
Source: S146
Wofür werden Zwillingsstudien eingesetzt? Was sind Vor- und Nachteile von Zwillingsstudien?
Zwillingsstudien:
Grundsätzliche Probleme von Zwillingsstudien:
- Eineiige Zwillinge (EZ) haben identische genetische Ausstattung.
- Zweieiige Zwillinge (ZZ) sind Geschwister gleichen Alters.
- Getrennt oder gemeinsam aufgewachsen?
- EZ, die getrennt aufgewachsen, unterscheiden sich voneinander nur durch die ungleichen ökologischen Faktoren (z.B. Bouchard, 1987) .
- Gemeinsam aufgewachsene EZ unterscheiden sich von gemeinsam aufgewachsenen ZZ nur durch die genetische Ähnlichkeit – bei angenommener gleicher Umweltvarianz (Loehlin, 1992).
Grundsätzliche Probleme von Zwillingsstudien:
- Repräsentativität von Zwillingen für die Normalbevölkerung als Ganzes, da sie Personen mit Erbkopien (EZ) bzw. Geschwister gleichen Alters (EZ und ZZ) sind.
- Wie verschieden bzw. unabhängig waren die jeweiligen Umwelten von getrennt aufgewachsenen Zwillingspaaren (EZ und ZZ) wirklich?
- Umweltvarianz wahrscheinlich geringer als in Normalbevölkerung.
Tags: Anlage/Umwelt, Methoden, Zwillingsmethode
Source: S146
Source: S146
Welche Schlussfolgerungen lassen sich in Bezug auf die Datengewinnungsmethoden in der Anlagen/Umweltforschung ziehen?
- Jeder Untersuchungsansatz birgt spezifische Probleme, so dass es zu einer Über- bzw. Unterschätzung der Heritabilität (Erblichkeit) kommen kann.
- Für inferenzstatistische Aussagen werden Zufallsstichproben aus der Population (bzw. repräsentative Stichproben) benötigt; Selektionseffekte, die durch Auswahl verschiedener spezifischer Personengruppen gegeben sind, verhindern die Erfüllung dieser Voraussetzung . D.h. sowohl die genetische Varianz als auch die Umweltvarianz entspricht in den speziellen Gruppen wahrscheinlich nicht der Populationsvarianz. Zudem sind die Stichproben häufig klein, so dass inferenzstatistische Aussagen problematisch sind.
- Alle Studien haben quasi-experimentellen Charakter, da es sich um „Subjektvariable“ handelt (Randomisierung bzw. Manipulation der „unabhängigen Variablen“ durch den Versuchsleiter nicht möglich).
Tags: Anlage/Umwelt, Methoden
Source: S147
Source: S147
Flashcard set info:
Author: ZoeSzapary
Main topic: Differenzielle Psychologie
Topic: Alle Kapitel
School / Univ.: Universität Wien
City: Wien
Published: 11.12.2019
Card tags:
All cards (221)
16 PF (9)
Abgrenzung (1)
Adoptionsmethode (1)
Aggregation (1)
Aktivität (2)
Analysatoren (1)
Anlage/Umwelt (13)
Anwendung (4)
Army-Alpha-Test (1)
Ausdruck (1)
Beispiel (3)
Big Five (11)
Binet (5)
Carroll (2)
CAT (1)
Cattell (17)
CHC (2)
Darwin (2)
Definition (13)
EEG (2)
Einstellungstyp (1)
Entstehung (1)
Entwicklung (1)
Erblichkeit (1)
Evolution (1)
Experiment (4)
Extraversion (7)
Eysenck (14)
Faktorenanalyse (11)
Faktorenmodell (1)
Fehr (1)
Felabhängigkeit (1)
Feldabhängigkeit (2)
fMRT (1)
Forschung (22)
Fragebogen (1)
Funktionstyp (1)
Galton (3)
Gardner (3)
Geschichte (11)
Gray (1)
HAWIE (1)
Hochbegabung (4)
Hofstätter (2)
Horn (3)
Intelligenz (41)
Intelligenzmodelle (17)
Intervention (1)
Jung (6)
Kagan (1)
Kelly (4)
Korrelation (5)
Kretschmer (1)
Kritik (12)
Mendel (1)
mental Speed (3)
mental speed (1)
Merkmal (1)
Methoden (22)
Neurotizismus (3)
Normalverteilung (1)
Norman (1)
Objektivität (1)
Persönlichkeit (36)
Persönlickeit (1)
PET (1)
Prozessmodell (1)
Psychographie (2)
Psychologie (2)
Psychometrie (1)
Psychotizismus (2)
Quasi-Experiment (1)
R/S Konstrukt (4)
Rasch-Modell (17)
Reflexivität (1)
Regression (2)
Repression (2)
Rogers (7)
Sensitization (2)
Sheldon (1)
Simon-Binet-Test (1)
Skala (1)
Spearman (4)
Stabilität (1)
Stern (10)
Sternberg (6)
Stimmung (1)
Strelau (3)
Streuung (1)
Struktur (1)
Superfaktoren (1)
Terman (2)
Test (10)
Testung (1)
Theorie (6)
Thurstone (2)
TMI (3)
Trait-Modell (7)
Typenlehre (1)
Unterschiede (1)
Variable (1)
Varianz (4)
Varianzzerlegung (1)
Vernon (2)
Wahrnehmung (1)
Wechsler (2)
Witkin (1)
working memory (2)
Zuckerman (3)
Zwillingsmethode (5)
